New week new exercises! Here's my answers for chapter 4 in An Introduction to Statistical Learning with Applications in R.
4. The curse of dimensionality
When the number of features p is large, there tends to be a deterioration in the performance of KNN and other local approaches that perform prediction using only observations that are near the test observation for which a prediction must be made. This phenomenon is known as the curse of dimensionality, and it ties into the fact that non-parametric approaches often perform poorly when p is large. We will now investigate this curse.
a.
Suppose that we have a set of observations, each with measurements on \(p = 1\) feature, \(X\). We assume that \(X\) is uniformly (evenly) distributed on \([0,1]\). Associated with each observation is a response value. Suppose that we wish to predict a test observation’s response using only observations that are within \(10\%\) of the range of \(X\) closest to that test observation. For instance, in order to predict the response for a test observation with \(X = 0.6\),we will use observations in the range \([0.55,0.65]\). On average, what fraction of the available observations will we use to make the prediction?
Naively, on average we would expect \(10\%\) of observations to be available but we must be careful at the boundaries of the feature. By intergrating two linear functions to describe each boundary we actually get that on average we have \(9.75\%\) of obervations available.
\(\int_{0.05}^{0.95}10dx+\int_{0}^{0.05}100x+5dx+\int_{0.95}^{1}105-100x-dx = 9+0.375+0.375=9.75\%\)
b.
Now suppose that we have a set of observations, each with measurements on \(p = 2\) features, \(X_1\) and \(X_2\). We assume that \((X_1,X_2)\) are uniformly distributed on \([0,1]\times[0,1]\). We wish to predict a test observation’s response using only observations that are within \(10\%\) of the range of \(X_1\) and within \(10\%\) of the range of \(X_2\) closest to that test observation. For instance, in order to predict the response for a test observation with \(X_1 = 0.6\) and \(X_2 = 0.35\), we will use observations in the range \([0.55, 0.65]\) for X1 and in the range \([0.3, 0.4]\) for X2. On average, what fraction of the available observations will we use to make the prediction?
Since \(X_1\) and \(X_2\) are uniformly and independently distributed we can assume that the fraction of available observations will just be the product of two equations identical to the one used in part a. Given this we can expect that \((9.75\times9.75)=0.950625\) or about \(1\%\) of observations will be available to make the prediction.
c.
Now suppose that we have a set of observations on \(p = 100\) features. Again the observations are uniformly distributed on each feature, and again each feature ranges in value from 0 to 1. We wish to predict a test observation’s response using observations within the \(10\%\) of each feature’s range that is closest to that test observation. What fraction of the available observations will we use to make the prediction?
Roughly \((9.75)^p=(9.75)^{100}\simeq0\%\) of the observations will be available to make the prediction!
5.
We now examine the differences between LDA and QDA.
a.
If the Bayes decision boundary is linear, do we expect LDA or QDA to perform better on the training set? On the test set?
One the training set we except the QDA to perform better as it is a more flexible form of fitting but is likely to overfit the training set data in this regard. On the test set we expect the LDA to perform better as it accurately parameterizes the form of the underlying decision boundary.
b.
If the Bayes decision boundary is non-linear, do we expect LDA or QDA to perform better on the training set? On the test set?
QDA for both.
c.
In general, as the sample size n increases, do we expect the test prediction accuracy of QDA relative to LDA to improve, decline, or be unchanged? Why?
As n increases we expect the test prediction accuracy of QDA to improve compared to LDA. Since QDA is more flexible, it can, in general, arrive at a better fit but if there is not a large enough sample size we will end up overfitting to the noise in the data. (A large n will help offset any variance in the data.
d.
True or False: Even if the Bayes decision boundary for a given problem is linear, we will probably achieve a superior test error rate using QDA rather than LDA because QDA is flexible enough to model a linear decision boundary. Justify your answer.
False. Depends on the sample size.
6.
Suppose we collect data for a group of students in a statistics class with variables \(X_1 =\) hours studied, \(X_2 =\) undergrad GPA, and \(Y =\) receive an A. We fit a logistic regression and produce estimated coefficient, \(\hat\beta_0 = −6, \hat\beta_1 = 0.05, \hat\beta_2 = 1\).
a.
Estimate the probability that a student who studies for 40 h and has an undergrad GPA of 3.5 gets an A in the class.
b.
How many hours would the student in part (a) need to study to have a 50 % chance of getting an A in the class?
Rough stuff! Sounds like a terrible class.
7.
Suppose that we wish to predict whether a given stock will issue a dividend this year (“Yes” or “No”) based on \(X\), last year’s percent profit. We examine a large number of companies and discover that the mean value of \(X\) for companies that issued a dividend was \(\bar X = 10\), while the mean for those that didn’t was \(\bar X = 0\). In addition, the variance of \(X\) for these two sets of companies was \(\hat\sigma^2 = 36\). Finally, \(80\%\) of companies issued dividends. Assuming that \(X\) follows a normal distribution, predict the probability that a company will issue a dividend this year given that its percentage profit was \(X = 4\) last year.
8.
Suppose that we take a data set, divide it into equally-sized training and test sets, and then try out two different classification procedures. First we use logistic regression and get an error rate of \(20\%\) on the training data and \(30\%\) on the test data. Next we use 1-nearest neighbors (i.e. \(K = 1\)) and get an average error rate (averaged over both test and training data sets) of \(18\%\). Based on these results, which method should we prefer to use for classification of new observations? Why?
I would prefer to use logistic regression. 1-nearest neighbors will overfit the data and yield a training error rate of \(0\%\). Hence the test error rate is actually \(36\%\) and worse than what is found with the logistic regression.
9.
This problem has to do with odds.
a.
On average, what fraction of people with an odds of \(0.37\) of defaulting on their credit card payment will in fact default?
b.
Suppose that an individual has a \(16\%\) chance of defaulting on her credit card payment. What are the odds that she will default?
10.
This question should be answered using the Weekly data set, which is part of the ISLR package. This data is similar in nature to the Smarket data from this chapter’s lab, except that it contains 1,089 weekly returns for 21 years, from the beginning of 1990 to the end of 2010.
a.
Produce some numerical and graphical summaries of the Weekly data. Do there appear to be any patterns?
library(ISLR)
attach(Weekly)
summary(Weekly)
Cor=cor(Weekly[,-9])
Cor
a <- as.data.frame(as.table(Cor))
a = subset(a, abs(Freq) > 0.5)
a
Year Lag1 Lag2 Lag3
Min. :1990 Min. :-18.1950 Min. :-18.1950 Min. :-18.1950
1st Qu.:1995 1st Qu.: -1.1540 1st Qu.: -1.1540 1st Qu.: -1.1580
Median :2000 Median : 0.2410 Median : 0.2410 Median : 0.2410
Mean :2000 Mean : 0.1506 Mean : 0.1511 Mean : 0.1472
3rd Qu.:2005 3rd Qu.: 1.4050 3rd Qu.: 1.4090 3rd Qu.: 1.4090
Max. :2010 Max. : 12.0260 Max. : 12.0260 Max. : 12.0260
Lag4 Lag5 Volume Today
Min. :-18.1950 Min. :-18.1950 Min. :0.08747 Min. :-18.1950
1st Qu.: -1.1580 1st Qu.: -1.1660 1st Qu.:0.33202 1st Qu.: -1.1540
Median : 0.2380 Median : 0.2340 Median :1.00268 Median : 0.2410
Mean : 0.1458 Mean : 0.1399 Mean :1.57462 Mean : 0.1499
3rd Qu.: 1.4090 3rd Qu.: 1.4050 3rd Qu.:2.05373 3rd Qu.: 1.4050
Max. : 12.0260 Max. : 12.0260 Max. :9.32821 Max. : 12.0260
Direction
Down:484
Up :605
| Year | Lag1 | Lag2 | Lag3 | Lag4 | Lag5 | Volume | Today | |
|---|---|---|---|---|---|---|---|---|
| Year | 1.00000000 | -0.03228927 | -0.03339001 | -0.03000649 | -0.03112792 | -0.03051910 | 0.84194162 | -0.03245989 |
| Lag1 | -0.032289274 | 1.000000000 | -0.074853051 | 0.058635682 | -0.071273876 | -0.008183096 | -0.064951313 | -0.075031842 |
| Lag2 | -0.03339001 | -0.07485305 | 1.00000000 | -0.07572091 | 0.05838153 | -0.07249948 | -0.08551314 | 0.05916672 |
| Lag3 | -0.03000649 | 0.05863568 | -0.07572091 | 1.00000000 | -0.07539587 | 0.06065717 | -0.06928771 | -0.07124364 |
| Lag4 | -0.031127923 | -0.071273876 | 0.058381535 | -0.075395865 | 1.000000000 | -0.075675027 | -0.061074617 | -0.007825873 |
| Lag5 | -0.030519101 | -0.008183096 | -0.072499482 | 0.060657175 | -0.075675027 | 1.000000000 | -0.058517414 | 0.011012698 |
| Volume | 0.84194162 | -0.06495131 | -0.08551314 | -0.06928771 | -0.06107462 | -0.05851741 | 1.00000000 | -0.03307778 |
| Today | -0.032459894 | -0.075031842 | 0.059166717 | -0.071243639 | -0.007825873 | 0.011012698 | -0.033077783 | 1.000000000 |
| Var1 | Var2 | Freq | |
|---|---|---|---|
| 1 | Year | Year | 1 |
| 7 | Volume | Year | 0.841941618703162 |
| 10 | Lag1 | Lag1 | 1 |
| 19 | Lag2 | Lag2 | 1 |
| 28 | Lag3 | Lag3 | 1 |
| 37 | Lag4 | Lag4 | 1 |
| 46 | Lag5 | Lag5 | 1 |
| 49 | Year | Volume | 0.841941618703162 |
| 55 | Volume | Volume | 1 |
| 64 | Today | Today | 1 |
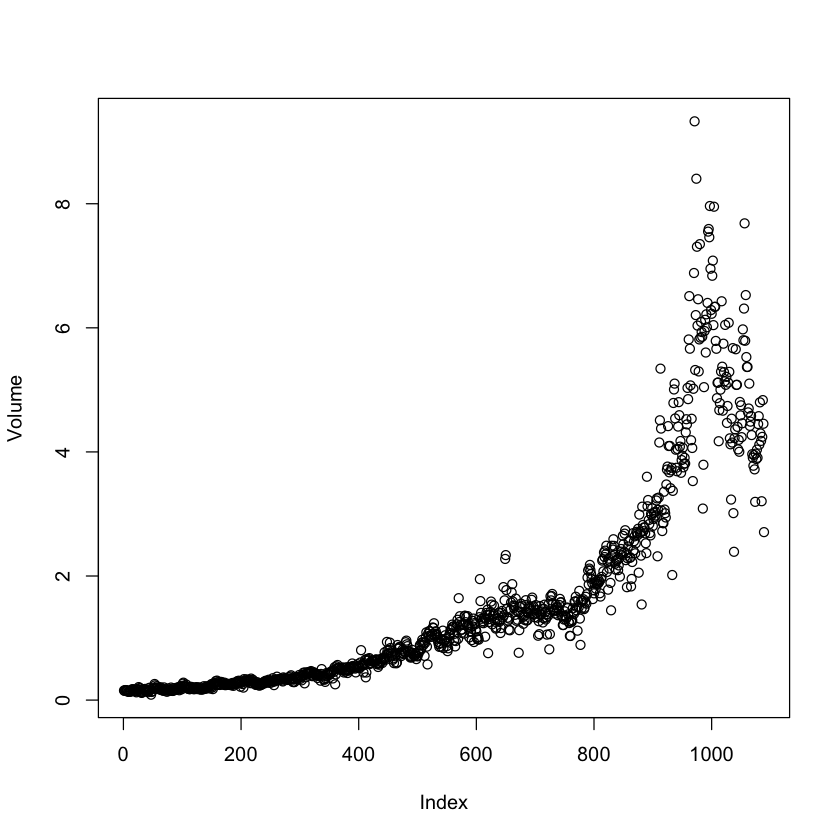
It appears that the only stong correlation present in the data is between Volume and time. Plotting the Volume confirms this.
plot(Volume)
b.
Use the full data set to perform a logistic regression with Direction as the response and the five lag variables plus Volume as predictors. Use the summary function to print the results. Do any of the predictors appear to be statistically significant? If so, which ones?
glm.fit = glm(Direction~.-Direction-Today-Year,data = Weekly,family=binomial)
summary(glm.fit)
Call:
glm(formula = Direction ~ . - Direction - Today - Year, family = binomial,
data = Weekly)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.6949 -1.2565 0.9913 1.0849 1.4579
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.26686 0.08593 3.106 0.0019 **
Lag1 -0.04127 0.02641 -1.563 0.1181
Lag2 0.05844 0.02686 2.175 0.0296 *
Lag3 -0.01606 0.02666 -0.602 0.5469
Lag4 -0.02779 0.02646 -1.050 0.2937
Lag5 -0.01447 0.02638 -0.549 0.5833
Volume -0.02274 0.03690 -0.616 0.5377
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1496.2 on 1088 degrees of freedom
Residual deviance: 1486.4 on 1082 degrees of freedom
AIC: 1500.4
Number of Fisher Scoring iterations: 4
Lag2 has a p value of 0.03 which is slightly significant if we accept 0.05 as our significance threshold.
c.
Compute the confusion matrix and overall fraction of correct predictions. Explain what the confusion matrix is telling you about the types of mistakes made by logistic regression.
glm.probs = predict(glm.fit, type="response")
glm.pred = rep("Down",length(glm.probs))
glm.pred[glm.probs > 0.5] = "Up"
table(glm.pred,Direction)
mean(glm.pred == Direction)
Direction
glm.pred Down Up
Down 54 48
Up 430 557
0.561065197428834
The diagonal elements of the confusion matrix provide the correct predictions. By taking the mean of the prediction we get the fraction of days that the fit was correct. Here it was correct on \(56\%\) of the days.
d.
Now fit the logistic regression model using a training data period from 1990 to 2008, with Lag2 as the only predictor. Compute the confusion matrix and the overall fraction of correct predictions for the held out data (that is, the data from 2009 and 2010).
train=(Year<2009)
glm.fit2 = glm(Direction~Lag2,family=binomial,subset=train)
glm.probs2 = predict(glm.fit2,Weekly[!train,],type="response")
glm.pred2 = rep("Down",length(glm.probs2))
glm.pred2[glm.probs2 >0.5] = "Up"
table(glm.pred2,Direction[!train])
mean(glm.pred2 == Direction[!train])
glm.pred2 Down Up
Down 9 5
Up 34 56
0.625
The correct percentage of predicitons is \(62.5\%\).
e.
Repeat (d) using LDA.
library(MASS)
lda.fit = lda(Direction~Lag2,subset=train)
lda.pred = predict(lda.fit,Weekly[!train,])
#The predict of the LDA function spits own class (similar to what it spits out for glm), posterior and the LDs (x).
lda.class = lda.pred$class
table(lda.class,Direction[!train])
mean(lda.class == Direction[!train])
lda.class Down Up
Down 9 5
Up 34 56
0.625
f.
Repeat (d) using QDA.
qda.fit = qda(Direction~Lag2,subset=train)
qda.pred = predict(qda.fit,Weekly[!train,])
qda.class = qda.pred$class
table(qda.class,Direction[!train])
mean(qda.class==Direction[!train])
qda.class Down Up
Down 0 0
Up 43 61
0.586538461538462
g.
Repeat (d) using KNN with \(K=1\).
library(class)
train.X = matrix(Lag2[train]) #Make sure these
test.X = matrix(Lag2[!train]) #are matrices.
train.Direction = Direction[train]
set.seed(1)
knn.pred = knn(train.X,test.X,train.Direction,k=1)
table(knn.pred,Direction[!train])
mean(knn.pred==Direction[!train])
knn.pred Down Up
Down 21 30
Up 22 31
0.5
h.
Which of these methods appears to provide the best results on this data? LDA and logistic regression have the best results
i.
Experiment with different combinations of predictors, including possible transformations and interactions, for each of the methods. Report the variables, method, and associated confusion matrix that appears to provide the best results on the held out data. Note that you should also experiment with values for K in the KNN classifier.
11.
In this problem, you will develop a model to predict whether a given car gets high or low gas mileage based on the Auto data set.
a.
Create a binary variable, mpg01, that contains a 1 if mpg contains a value above its median, and a 0 if mpg contains a value below its median. You can compute the median using the median() function. Note you may find it helpful to use the data.frame() function to create a single data set containing both mpg01 and the other Auto variables.
attach(Auto)
summary(Auto)
mpg01 = rep(0,length(mpg))
mpg01[mpg>median(mpg)] = 1
Auto01 = data.frame(Auto,mpg01)
mpg cylinders displacement horsepower weight
Min. : 9.00 Min. :3.000 Min. : 68.0 Min. : 46.0 Min. :1613
1st Qu.:17.00 1st Qu.:4.000 1st Qu.:105.0 1st Qu.: 75.0 1st Qu.:2225
Median :22.75 Median :4.000 Median :151.0 Median : 93.5 Median :2804
Mean :23.45 Mean :5.472 Mean :194.4 Mean :104.5 Mean :2978
3rd Qu.:29.00 3rd Qu.:8.000 3rd Qu.:275.8 3rd Qu.:126.0 3rd Qu.:3615
Max. :46.60 Max. :8.000 Max. :455.0 Max. :230.0 Max. :5140
acceleration year origin name
Min. : 8.00 Min. :70.00 Min. :1.000 amc matador : 5
1st Qu.:13.78 1st Qu.:73.00 1st Qu.:1.000 ford pinto : 5
Median :15.50 Median :76.00 Median :1.000 toyota corolla : 5
Mean :15.54 Mean :75.98 Mean :1.577 amc gremlin : 4
3rd Qu.:17.02 3rd Qu.:79.00 3rd Qu.:2.000 amc hornet : 4
Max. :24.80 Max. :82.00 Max. :3.000 chevrolet chevette: 4
(Other) :365
b.
Explore the data graphically in order to investigate the association between mpg01 and the other features. Which of the other features seem most likely to be useful in predicting mpg01? Scatterplots and boxplots may be useful tools to answer this question. Describe your findings.
cor(Auto01[,-9])
pairs(Auto01)
| mpg | cylinders | displacement | horsepower | weight | acceleration | year | origin | mpg01 | |
|---|---|---|---|---|---|---|---|---|---|
| mpg | 1.0000000 | -0.7776175 | -0.8051269 | -0.7784268 | -0.8322442 | 0.4233285 | 0.5805410 | 0.5652088 | 0.8369392 |
| cylinders | -0.7776175 | 1.0000000 | 0.9508233 | 0.8429834 | 0.8975273 | -0.5046834 | -0.3456474 | -0.5689316 | -0.7591939 |
| displacement | -0.8051269 | 0.9508233 | 1.0000000 | 0.8972570 | 0.9329944 | -0.5438005 | -0.3698552 | -0.6145351 | -0.7534766 |
| horsepower | -0.7784268 | 0.8429834 | 0.8972570 | 1.0000000 | 0.8645377 | -0.6891955 | -0.4163615 | -0.4551715 | -0.6670526 |
| weight | -0.8322442 | 0.8975273 | 0.9329944 | 0.8645377 | 1.0000000 | -0.4168392 | -0.3091199 | -0.5850054 | -0.7577566 |
| acceleration | 0.4233285 | -0.5046834 | -0.5438005 | -0.6891955 | -0.4168392 | 1.0000000 | 0.2903161 | 0.2127458 | 0.3468215 |
| year | 0.5805410 | -0.3456474 | -0.3698552 | -0.4163615 | -0.3091199 | 0.2903161 | 1.0000000 | 0.1815277 | 0.4299042 |
| origin | 0.5652088 | -0.5689316 | -0.6145351 | -0.4551715 | -0.5850054 | 0.2127458 | 0.1815277 | 1.0000000 | 0.5136984 |
| mpg01 | 0.8369392 | -0.7591939 | -0.7534766 | -0.6670526 | -0.7577566 | 0.3468215 | 0.4299042 | 0.5136984 | 1.0000000 |

par(mfrow=c(2,3))
boxplot(mpg~mpg01,main="mpg vs. mpg01")
boxplot(cylinders~mpg01,main="cylinders vs. mpg01")
boxplot(displacement~mpg01,main="displacement vs. mpg01")
boxplot(weight~mpg01,main="weight vs. mpg01")
boxplot(horsepower~mpg01,main="horsepower vs. mpg01")
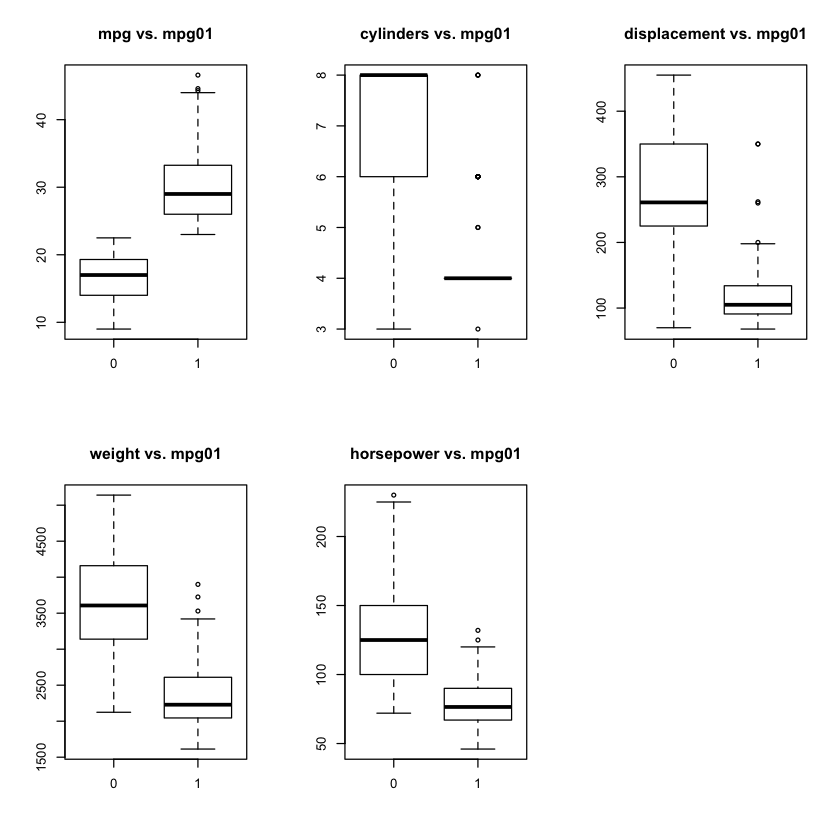
mpg, cylinders, displacement, weight and horsepower all appear to have some relation to mpg01.
c.
Split the data into a test set and training set.
train = (year %% 2 == 0)
Auto.train = Auto[train,]
Auto.test = Auto[!train,]
mpg01.test = mpg01[!train]
d.
Perform LDA on the training data in order to predict mpg01 using the variables that seemed most associated with mpg01 in (b). What is the test error of the model obtained?
lda.fit2 = lda(mpg01~mpg+cylinders+weight+displacement+horsepower,data = Auto,subset=train)
lda.pred2 = predict(lda.fit2,Auto.test)
lda.class2 = lda.pred2$class
table(lda.class2, mpg01.test)
mean(lda.class2 != mpg01.test)
mpg01.test
lda.class2 0 1
0 88 6
1 12 76
0.0989010989010989
The test error rate is \(\sim10\%\).
e.
Now for QDA.
qda.fit2 = qda(mpg01~mpg+cylinders+weight+displacement+horsepower,data = Auto,subset=train)
qda.pred2 = predict(qda.fit2,Auto.test)
qda.class2 = qda.pred2$class
table(qda.class2,mpg01.test)
mean(qda.class2 != mpg01.test)
mpg01.test
qda.class2 0 1
0 89 9
1 11 73
0.10989010989011
f.
And for Logistic Regression.
glm.fit3 = glm(mpg01~cylinders + weight + displacement + horsepower, family = binomial,subset=train)
glm.probs3 = predict(glm.fit3,Auto.test,type="response")
glm.pred3 = rep(0, length(glm.probs3))
glm.pred3[glm.probs3 > 0.5] = 1
mean(glm.pred3 != mpg01.test)
0.120879120879121
g.
And finally KNN with several values of K. What is the best value for K?
12.
This problem involves writing functions.
a.
Write a function, Power(), that prints out the result of raising 2 to the 3rd power. In other words, your function should compute \(2^3\) and print out the results.
Power = function() {
2^3
}
print(Power())
[1] 8
b.
Create a new function, Power2(), that allows you to pass any two numbers, x and a, and prints out the value of x^a.
Power2 = function(x,a) {
print(x^a)
}
Power2(3,8)
[1] 6561
d.
Now create a new function, Power3(), that actually returns the result x^a as an R object, rather than simply printing it to the screen.
Power3 = function(x,a) {
return(x^a)
}
Power3(3,8)
6561
e.
Now using the Power3() function, create a plot of f(x) = x2. The x-axis should display a range of integers from 1 to 10, and the y-axis should display x2. Label the axes appropriately, and use an appropriate title for the figure.
x = 1:10
plot(x, Power3(x, 2), log = "xy", ylab = "Log of y = x^2", xlab = "Log of x",
main = "Log of x^2 versus Log of x")
f.
Create a function, PlotPower(), that allows you to create a plot of x against x^a for a fixed a and for a range of values of x. For instance, if you call
PlotPower = function(x,a) {
plot(x, Power3(x, a), log = "xy", ylab = sprintf("Log of y = x^%d",a),
xlab = "Log of x", main = sprintf("Log of x^%d versus Log of x",a))
}
PlotPower(1:10 ,3)